手机号 MDL 评分排序器
我用 Python 脚本基于最小描述长度也就是 MDL 的方式,为 11 位中国大陆手机号计算分数并排序。脚本支持多进程并行,并提供解释模式输出诊断信息,方便复核得分来源。
MISSION BRIEFING
数据分析项目,用 MDL 给手机号打分
评分口径
节省比特数
相对 IID 基线,每位 log2(10),节省的比特越多,说明序列在编码意义上更有规律。
多视角变换
66 种
把原序列、一阶差分与二阶差分分别做旋转与正反向处理,总计 66 个可逆视角,用来覆盖不同类型的规律。
编码器族
KTSeq、LZ78 以及 Renewal
把上下文统计、字典压缩以及周期复用三种编码方式组合在一起,让不同类型的规律都能被纳入评分。
最优分段
DP
用动态规划在 11 位上选择分段与编码器组合,避免手写规则。
混合模型
log-sum-exp
把多个视角的结果用 log-sum-exp 做混合,并加入惩罚项,让分数对单一视角不过度敏感。
工程化
并行并限载
多进程评分并自动分块,也可以选用 psutil 来控制目标 CPU 利用率。
SCREEN TOUR
项目展示
点击图片可放大查看
页面列表
点击缩略图切换;点击右侧大图可放大查看
当前预览
点击图片可放大查看;放大后支持:滚轮缩放 · 拖拽平移 · ←/→ 切图 · Esc 关闭
在命令行里运行脚本时,会输出处理进度,并且生成结果文件
项目概述
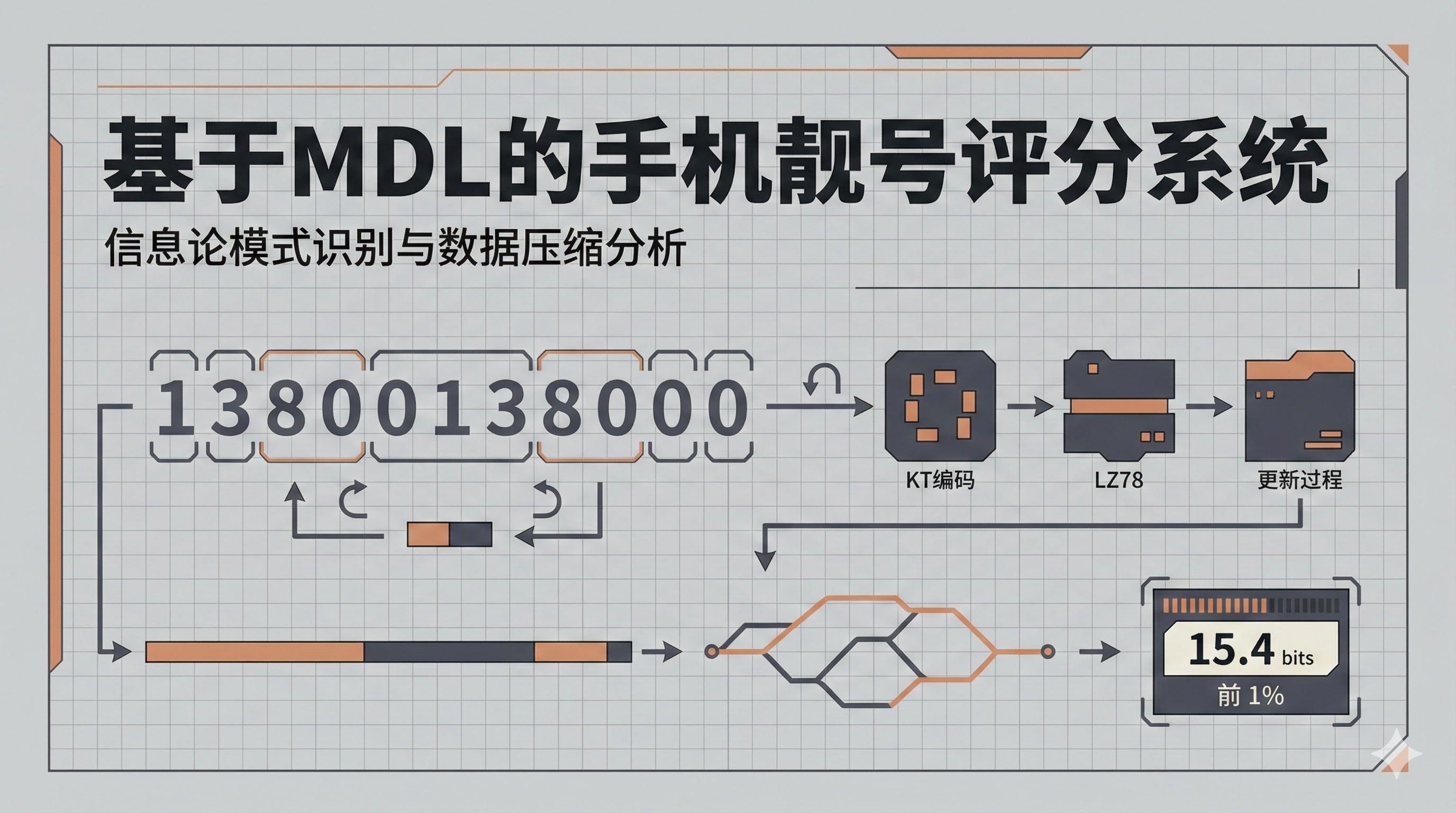
这个项目是一个可直接运行的 Python 脚本,用来给 11 位中国大陆手机号做评分并排序。输入是一列手机号的 CSV 文件,脚本会输出排序后的结果表,并且可以额外生成一份诊断表,用来解释分数从哪里来。
评分的核心思路来自最小描述长度,也就是 MDL。脚本把手机号视为长度为 11 的数字序列,并用通用编码器去描述它。如果一个号码包含重复、周期或者上下文规律,编码器通常能用更短的编码长度来表示它。脚本把这种编码长度上的节省换算成比特数,作为 score_bits_saved,并把它作为排序依据。
评分方法
脚本会先把手机号转换为 11 位数字序列,然后为同一个号码生成多个可逆视角。视角包含原始序列、一阶差分 mod 10、二阶差分 mod 10,并且会对每个视角做旋转与反向处理,总共得到 66 种变换版本。这样做的目的,是让不同类型的规律在某些视角下更容易被捕捉到。
对于每个变换版本,脚本会用动态规划在 11 位上做分段,并为每一段选择一个编码器。编码器包含 KTSeq、LZ78 以及 Renewal,它们分别对应上下文统计、字典压缩以及周期结构复用。为了避免分段过碎导致过拟合,脚本对分段数量和编码器切换加入惩罚项。
在得到每个视角的总编码长度后,脚本会用 log-sum-exp 对多个视角做混合,同时对视角选择也加入惩罚项。最终分数定义为 baseline_bits 与混合编码长度的差值。
score_bits_saved = baseline_bits - mixed_code_length
其中 baseline_bits 采用 IID 假设下每位 log2(10) 的总和。
输出结果
脚本默认输出一份主结果 CSV,包含 phone, score_bits_saved, rank。如果加上 --explain,脚本还会输出一份诊断 CSV,其中包含最佳视角、混合与单视角编码长度、分段细节以及 tie-break 信息,用来复核分数接近时的排序依据。
使用方式
# 输入文件为 numbers.csv,单列,无表头
python score_numbers.py --input numbers.csv --output numbers_scored.csv
# 并行加速,指定进程数并控制 CPU 占用目标
python score_numbers.py --workers 16 --target-cpu 0.8
# 生成解释性诊断表
python score_numbers.py --explain
默认严格要求每行是 11 位数字。非 strict 模式会把非法行记录到 invalid_rows.log,但不会中断整批任务。